Результаты предыдущих шагов могут быть подвергнуты серьёзной критике, причиной которой является присутствие в регрессионных моделях переменной  (уровень образования) в явном виде. Так получилось, что при сборе данных была принята система, в которой более высокому уровню образования соответствует более высокое значение переменной . Благодаря этому полученные результаты выглядят правдоподобно, но не более того. Присутствие в регрессионной модели переменной в явном виде по сути означает, что мы допускаем операцию сложения таких переменных, например: 2 (начальное ремесленное образование) + 3 (среднее образование) = 5 (университетское образование), что, конечно же, неверно. Очевидно, что если бы была выбрана другая система кодирования, не такая "логичная", то и результаты могли получиться совсем другими и, весьма вероятно, уровень образования оказался бы незначащим фактором.
(уровень образования) в явном виде. Так получилось, что при сборе данных была принята система, в которой более высокому уровню образования соответствует более высокое значение переменной . Благодаря этому полученные результаты выглядят правдоподобно, но не более того. Присутствие в регрессионной модели переменной в явном виде по сути означает, что мы допускаем операцию сложения таких переменных, например: 2 (начальное ремесленное образование) + 3 (среднее образование) = 5 (университетское образование), что, конечно же, неверно. Очевидно, что если бы была выбрана другая система кодирования, не такая "логичная", то и результаты могли получиться совсем другими и, весьма вероятно, уровень образования оказался бы незначащим фактором.
Введём новые фиктивные переменные по следующему правилу:
Каждая фиктивная переменная

может принимать значение 1, только если уровень образования равен

. Таким образом, для каждого наблюдения в исходной выборке будет только одна переменная
, значение которой равно 1, значения остальных фиктивных переменных будут равны 0 (нулю).
Возьмём в качестве основы модель (80) и сделаем в ней замену переменной на переменные . Здесь возможно несколько вариантов, главное – не попасть в "ловушку фиктивных переменных", например:
|
 , |
|
или
|
 , |
|
или
|
 , |
|
или даже такой вариант
|
 . |
|
Заметим, что хотя в последнем варианте присутствуют все пять фиктивных переменных , это, тем не менее, не приводит в "ловушку фиктивных переменных" в отличие от следующего варианта
|
 . |
|
Выбор того или иного варианта ввода фиктивных переменных обусловлен удобством дальнейшей интерпретации результатов. Пусть для определённости выбрана модель (93). Результаты оценки неизвестных параметров этой модели представлены на рис. 73.
Рис. 73. Результаты оценивания параметров модели (
93),
все факторы значимы на 5% и 1% уровнях значимости
Анализируя полученные результаты, замечаем, что все коэффициенты модели статистически значимы на 5% и 1% уровне значимости и имеют правильные знаки, коэффициент детерминации принял достаточно высокое значение. Таким образом, качество модели можно признать удовлетворительным. Сравнивая оценки неизвестных коэффициентов 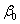 ,
, 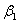 и
и 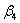 с результатами оценивания модели (80) (см. рис. 70), замечаем, что они изменились незначительно.
с результатами оценивания модели (80) (см. рис. 70), замечаем, что они изменились незначительно.
Найдём теперь возраст, в котором работающие граждане Нидерландов получают свою максимальную заработную плату, и сравним с полученными ранее результатами. Для этого представим правую часть модели (93) в виде функции от переменной 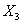 , т.е.
, т.е.
|
 , |
|
где

– некоторая константа, в которую вошли все слагаемые в правой части модели (
94), не содержащие переменную
, а переменные

,

,

,

и

(уровни образования) выступают в роли параметров.
Необходимое условие экстремума в данном случае примет вид
|
 , |
|
откуда получаем выражение для искомой величины
|
 . |
|
Заменяя в выражении (97) неизвестные параметры  ,
,  ,
, ,
,  и
и  их оценками (см. рис. 73) и присваивая поочерёдно одному из параметров , , , и значение 1, а остальным – значение 0 (ноль), получим следующие оценки искомого возраста для каждого из пяти уровней образования:
их оценками (см. рис. 73) и присваивая поочерёдно одному из параметров , , , и значение 1, а остальным – значение 0 (ноль), получим следующие оценки искомого возраста для каждого из пяти уровней образования:
|
 , |
|
|
 , |
|
|
 , |
|
|
 , |
|
|
 . |
|
Сравнивая полученные значения с полученными ранее результатами (84) – (88), делаем вывод, что расхождение незначительное (что можно объяснить только счастливой случайностью). На рис. 74 и 75 изображены графики прогнозов размера заработной платы мужчин и женщин соответственно, выполненные по результатам оценки параметров модели (93).
Рис. 74. Прогноз размера заработной платы мужчин от возраста
при различных уровнях образования, выполненный по результатам оценивания модели (
93)
Рис. 75. Прогноз размера заработной платы женщин от возраста
при различных уровнях образования, выполненный по результатам оценивания модели (
93)



